

What is Microsoft's BEIT-3?
www.ai-supremacy.com
What is Microsoft's BEIT-3?
A general-purpose multimodal foundation model.

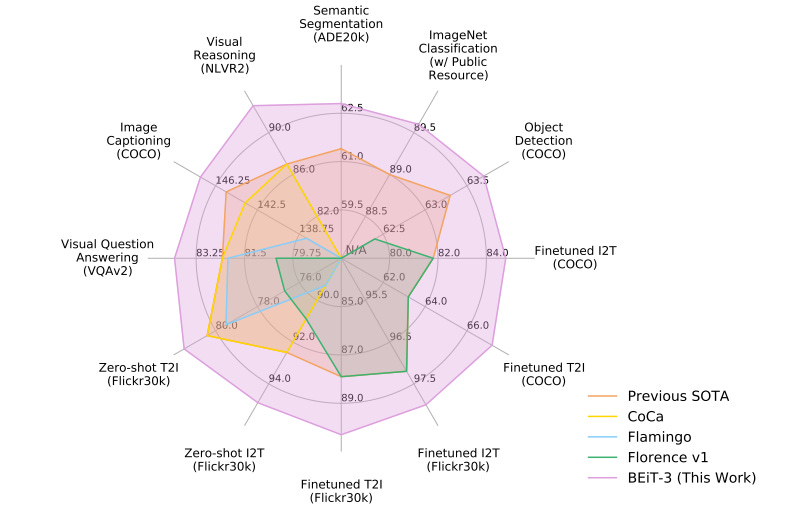
https://arxiv.org/pdf/2208.10442.pdf
Hey Guys,
This is AI Supremacy Premium.
A Microsoft research team recently presented BEiT-3 (BERT Pretraining of Image Transformers), a general-purpose state-of-the-art multimodal foundation model for both vision and vision-language tasks, in the paper Image as a Foreign Language: BEiT Pretraining for All Vision and V…
Keep reading with a 7-day free trial
Subscribe to AI Supremacy to keep reading this post and get 7 days of free access to the full post archives.