

AI Tidbits April round-up
AI Tidbits April round-up
🚀 I invited the author of Tidbits to round-up the A.I. News of April for us in one article.


Welcome Back,
Editor’s Note: Today we get to read Sahar Mor, who is a product Lead at Stripe. His minimalistic summaries of A.I. news are a hit. He promises us No personal takes, No summaries, and No endless scrolling: 🚀
You can catch his LinkedIn posts here (I recommend a Super follow).
If you are interested in a Guest post on A.I. Supremacy contact me in a DM here and pitch me your topic.
A lot happend in A.I. in just April, 2023. So get comfortable, get ready.
It’s time to 🤿 dive right in.
By
May, 2023.Click on the Title of this article if Gmail is saying it’s over the limit, for the best reading experience always read on the web.
AI Tidbits April Roundup
April was an exciting month for generative AI with a veritable treasure trove of progress: the open-source large language models space witnessed the emergence of groundbreaking models like Dolly 2.0, HuggingChat, and WebLLM and large Multimodal Models in the form of MiniGPT-4 and LLaVA have taken center stage, unlocking unparalleled potential in the fusion of AI capabilities.
Moreover, brace yourselves for the AutoGPT revolution as Automated GPT agents, such as BabyAGI and AutoGPT, make their mark in diverse use cases, from an automated sales representative to a new frontend developer colleague.
This month's highlights also include Meta's game-changing Segment Anything, the first foundation model for image segmentation, cutting-edge prompting techniques like Self-Refine, and an insightful glimpse into the future with Sam Altman's note on the highly anticipated GPT-5.
Large Language Models (LLMs)
Hugging Face introduces HuggingChat, an open source alternative to ChatGPT
Stability AI releases StableLM - their first-ever commercially available LLMs with 3B and 7B parameters models and more powerful ones to follow
CMU and OctoML release WebLLM, bringing instruction fine-tuned LLMs to the browser
Bloomberg announces BloombergGPT - an LLM trained on financial data to support financial NLP tasks

Multimodal

AutoGPT
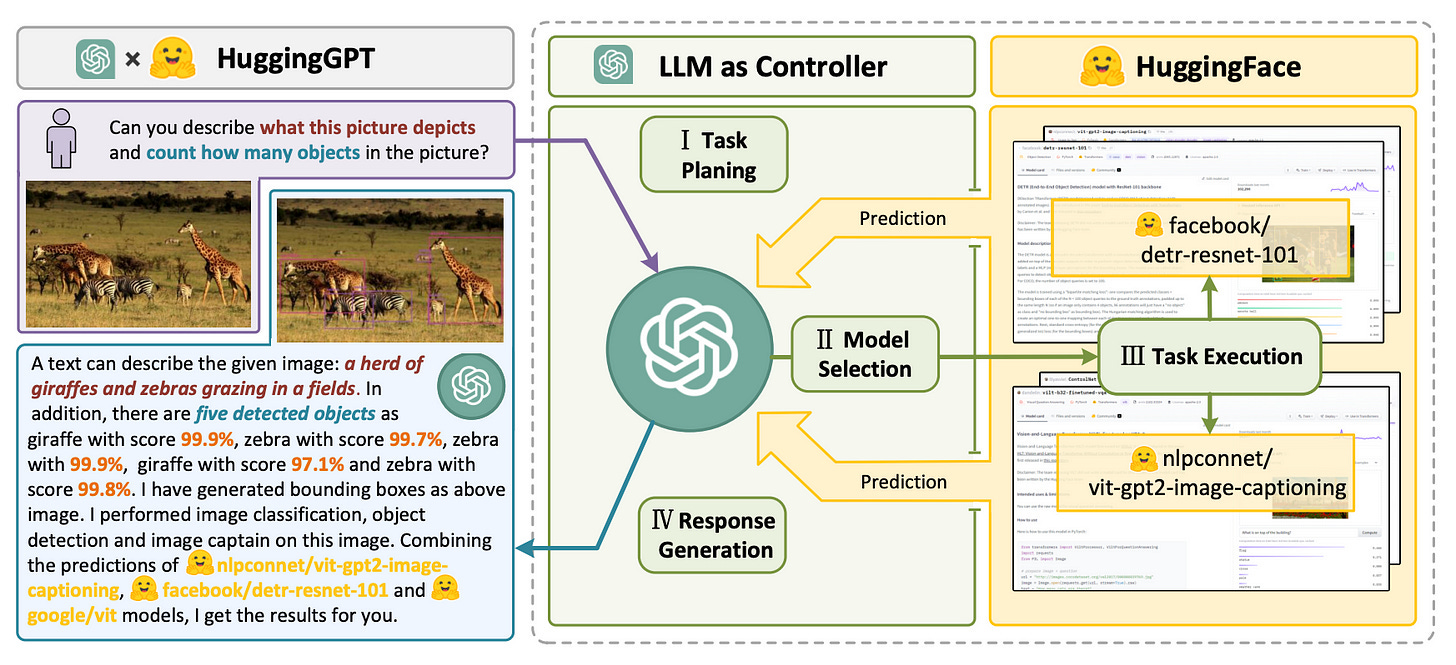
Vision

Join Premium 🌟🏆🚀
Video

Audio

Prompting

Open-source packages
DeepSpeed-Chat: easy and fast RLHF training of ChatGPT-like models
GPT4All-J - the first Apache-2 licensed chatbot that runs locally
LLaMA-Adapter - a lightweight method for fine-tuning instruction-following LLaMA models
Lit-LLaMA - implementation of the LLaMA language model based on nanoGPT for commercial use
Other
Stanford and Google researchers showcase a tiny Sims-like town with AI agents that act as humans
Sam Altman confirms OpenAI won't be developing GPT-5 any time soon

AI Tidbits April rounds-ups

Thanks for skimming! 🔮
After just 16 months of operations, A.I. Supremacy is a top #35 Newsletter on Substack’s Technology category.

 | A guest post by
|